1. 普通神经网络 手写数字识别
1 | """ |
1.1. 使用交叉熵损失
model.compile之前用的loss函数是mse均方误差,现在修改为categorical_crossentropy交叉熵,再训练,你会发现效果稍微好一点1
2
3
4
5model.compile(
optimizer=sgd,
loss='categorical_crossentropy', # 设置交叉熵损失函数categorical_crossentropy,
metrics=['accuracy']
)
1.2. 构建多层网络
构建3层,效果更好1
2
3
4
5
6
7
8model = Sequential([
# 784 -> 200
Dense(input_dim=784, units=200, bias_initializer='one', activation='tanh'),
# 200 -> 100,"input_dim=200"可以直接省略
Dense(units=100, bias_initializer='one', activation='tanh'),
# 100 -> 10
Dense(units=10, bias_initializer='one', activation='softmax'),
])
结果1
2
3
4
5
655000/55000 [==============================] - 1s 17us/step
train loss: 0.007714528205446814
train accuracy: 0.9985636363636363
10000/10000 [==============================] - 0s 17us/step
test loss: 0.07307906513710914
test accuracy: 0.9797
1.3. 添加Dropout防止过拟合
1 | from keras.layers import Dropout |
可以看到,加了Dropout,准确率反而下降了。在这个例子中,仅仅是了解一下如何使用Dropout,目的不是为了提高准确率1
2
3
4
5
655000/55000 [==============================] - 1s 18us/step
train loss: 0.07450573552753777
train accuracy: 0.9771818181818182
10000/10000 [==============================] - 0s 20us/step
test loss: 0.10471451835799962
test accuracy: 0.9694
1.4. 正则化防止过拟合
1 | from keras.regularizers import l2 |
结果1
2
3
4
5
655000/55000 [==============================] - 1s 18us/step
train loss: 0.13682303088795056
train accuracy: 0.9874181818181819
10000/10000 [==============================] - 0s 19us/step
test loss: 0.16329636447429657
test accuracy: 0.9764
1.5. 使用Adam优化器
1 | from keras.optimizers import Adam |
1.6. 保存和加载模型
在训练完之后,可以保存模型1
2
3
4"""
保存模型
"""
model.save("mymodel")
之后可以直接加载模型,进行预测1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30from keras.models import load_model
from tensorflow.examples.tutorials.mnist import input_data
"""
读取数据
"""
mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True)
x_train, y_train = mnist.train.images, mnist.train.labels
x_test, y_test = mnist.test.images, mnist.test.labels
x_train = x_train.reshape([-1, 28, 28])
x_test = x_test.reshape([-1, 28, 28])
"""
加载模型
"""
model = load_model("mymodel")
"""
评估
"""
# 用模型预测 训练集
loss, accuracy = model.evaluate(x_train, y_train)
print('train loss: ', loss)
print('train accuracy: ', accuracy)
# 用模型预测 测试集
loss, accuracy = model.evaluate(x_test, y_test)
print('test loss: ', loss)
print('test accuracy: ', accuracy)
2. CNN 手写数字识别
1 | """ |
结果1
2
3
4
5
655000/55000 [==============================] - 19s 351us/step
train loss: 0.02459700823045251
train accuracy: 0.9924909090909091
10000/10000 [==============================] - 4s 353us/step
test loss: 0.04115021191320848
test accuracy: 0.9863
3. RNN 手写数字识别
1 | """ |
结果如下,显然RNN不如CNN效果好。CNN多用于处理图像,RNN多用于处理序列式问题,如文本1
2
3
4
5
655000/55000 [==============================] - 2s 45us/step
train loss: 0.33378106603405694
train accuracy: 0.9025636363636363
10000/10000 [==============================] - 0s 40us/step
test loss: 0.3353205518245697
test accuracy: 0.9036
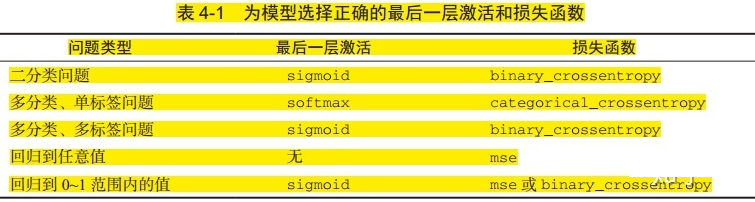
4. 激活函数和损失函数的选择