1. Seq2Seq的应用
1.1. 机器翻译
机器翻译最早期是逐字翻译。缺点很明显,翻译很不流畅,读起来很别扭

后来人们尝试根据统计学和概率来做机器翻译。每个词都有对应翻译的候选值,各个词之间的候选值组合成一句话,选择其中一个概率最大的组合
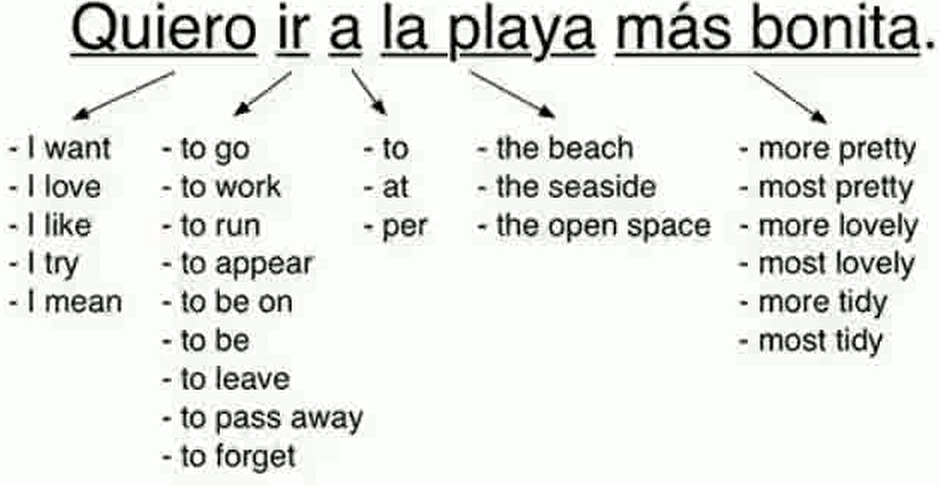
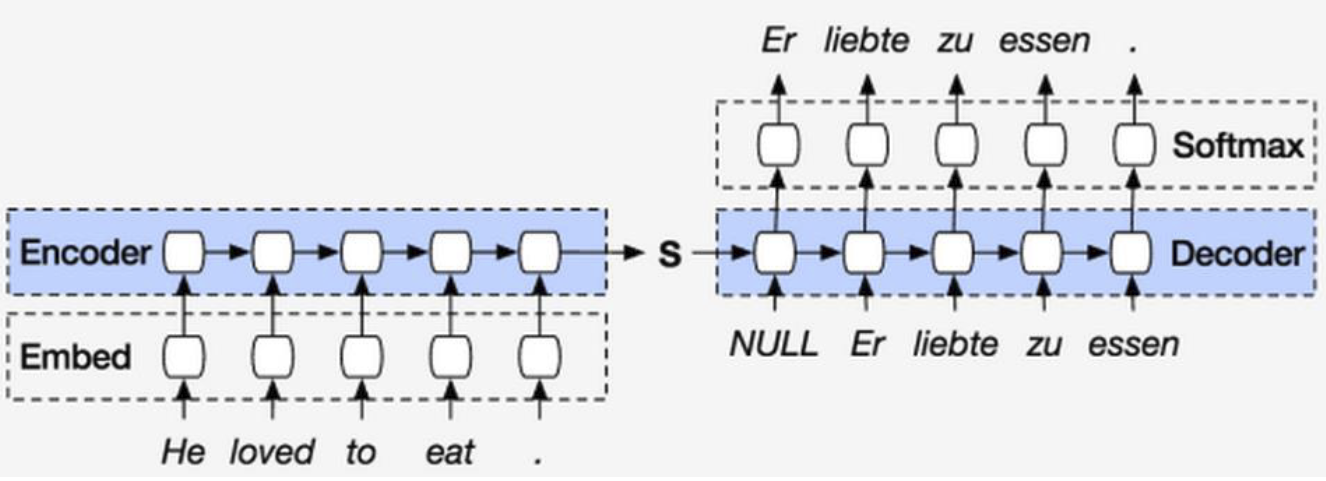
现在主流的做法是基于循环网络和编码。这里的编码是指将用户输入的话(序列)转化成一个向量,经过一些网络结构,最后再将向量解码得到另一种自然语言
输入是序列,输出是序列,中间要经过编码和解码,这就是Seq2Seq
1.2. 文本摘要

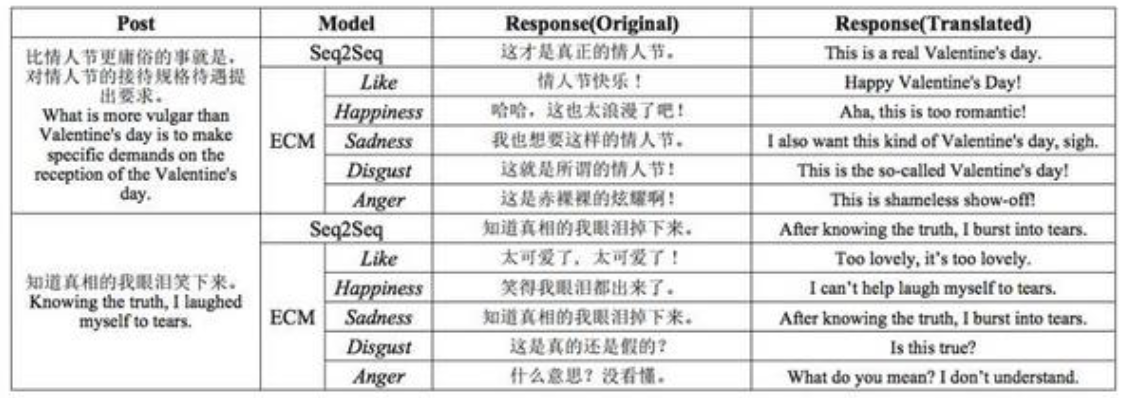
1.3. 情感对话生成
2. Seq2Seq网络架构
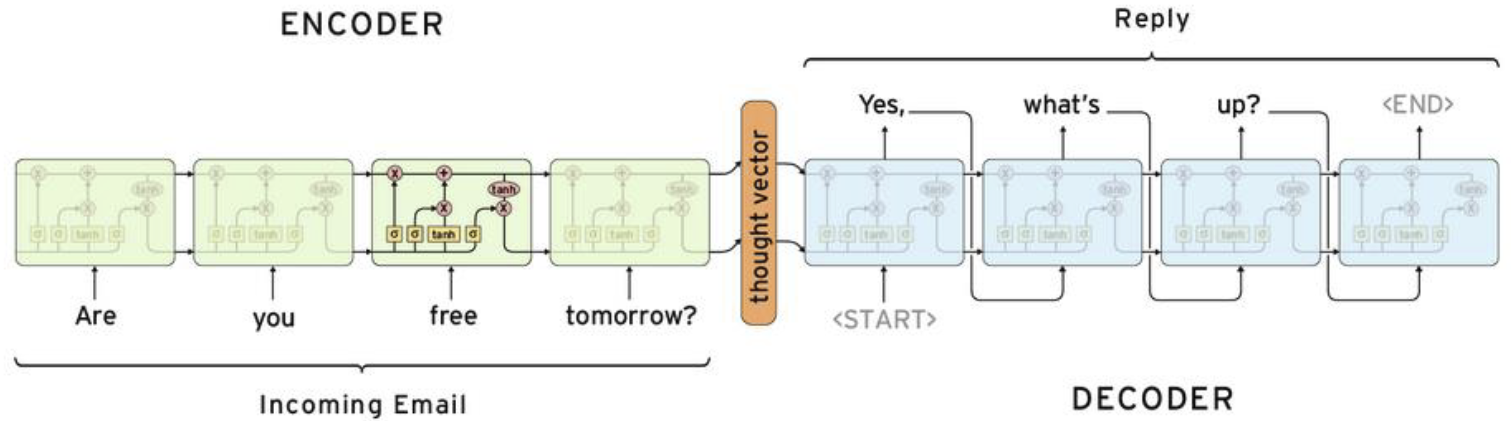
在解码过程中,可以看到 <END> ,有时也写为 <EOS>(End Of Sentence) ,代表终止字符。在解码时,不能让数据无限制地解码下去,所以要设置一个终止字符
3. Seq2Seq存在的问题
前面压缩损失了信息,解码时忽略了这一问题,会导致问题
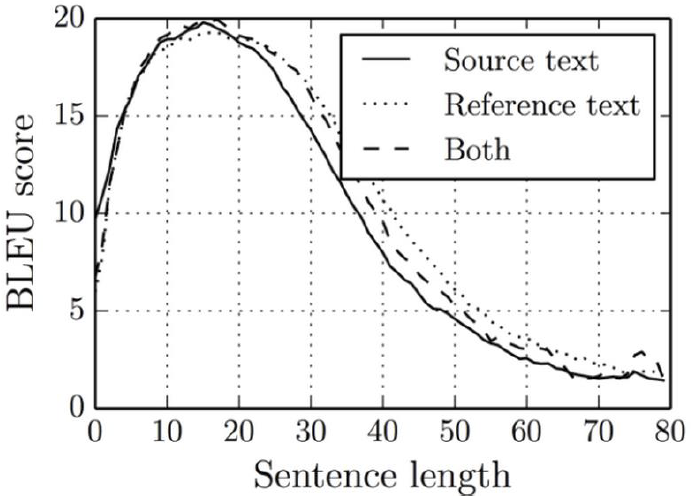
输入的序列不能过长。长度在10~20之间是最合适的