1. Windows JavaClient环境搭建
1.1. client添加HDFS节点的hostname记录
编辑系统hosts文件,添加以下记录。client请求NameNode操作HDFS时,NameNode会让client根据DataNode的hostname去找DataNode,请求执行相应的操作。如果client不知道DataNode的hostname对应的IP,就无法操作。client可以直接用IP访问NameNode,所以NameNode的hostname记录不一定要有,但是DataNode一定要有
1 | 192.168.57.101 hadoop1 |
1.2. 导入依赖
添加hadoop-common、hadoop-client、hadoop-hdfs三个依赖,版本与服务器的Hadoop要对应。
1 | <properties> |
1.3. 添加HDFS配置文件
无论是HDFS Shell还是JavaClient,执行操作时都会读取默认配置文件(core-default.xml、hdfs-default.xml)和自定义配置文件(core-site.xml和hdfs-site.xml)
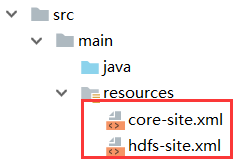
默认配置文件已经存在于依赖的jar包中。所以,只需要将Hadoop服务器的HDFS自定义配置文件(core-site.xml和hdfs-site.xml)复制到 src/main/resources目录下
1.4. 解决HDFS用户权限问题
客户端在操作HDFS时,默认是以执行客户端的系统用户作为操作HDFS的用户
- Linux中,root用户执行HDFS Shell时,操作HDFS的用户就是root
- Windows JavaClient执行操作时,操作的用户就是windows当前用户,如Administrator
而HDFS的文件系统和Linux文件系统一样,是有权限的,所以客户端不一定有足够的权限来执行相应的操作。
1 | $ hdfs dfs -ls -d / # 查看根目录的ownership和mode |
1.4.1. 测试运行 JavaAPI
1 | public class HdfsClientDemo { |
运行 testRead,程序正常执行。运行 testWrite,程序报错:
1 | org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="/":root:root:drwxr-xr-x |
执行JavaClient的是windows用户Administrator,而HDFS根目录的ownership是root:root,mode是drwxr-xr-x。其它用户有读权限,所以testRead能正常运行。但是其它用户没有写权限,所以执行testWrite就失败了。
1.4.2. 解决方式1:修改所有HDFS文件的所有者或mode(不推荐)
修改HDFS文件的所有者为运行client的windows用户,这样client就能执行写操作了
1 | hdfs dfs -chown -R Administrator / |
也可以修改HDFS文件的mode,为所有用户添加写权限,也可以直接设置为777,这样所有用户都能执行任何操作了
1 | hdfs dfs -chmod -R +w / # 为所有用户添加写权限 |
因为涉及文件信息的修改,所以不推荐以上方式
1.4.3. 解决方式2:编辑hdfs.site.xml,不对用户权限进行检测(不推荐)
服务器端编辑hdfs.site.xml,添加以下内容,再给javaclient同步一份。
1 | <property> |
不检查用户权限。任何用户可以对HDFS做任何操作,不安全,所以不推荐这样做。
1.4.4. 解决方式3:client配置HADOOP_USER_NAME环境变量(推荐)
client配置HADOOP_USER_NAME环境变量之后,操作HDFS的用户不再是运行client的系统用户了,而是${HADOOP_USER_NAME}。因为现在HDFS上的文件所有者是root,所以配置HADOOP_USER_NAME的值为root。
方式一:添加环境变量
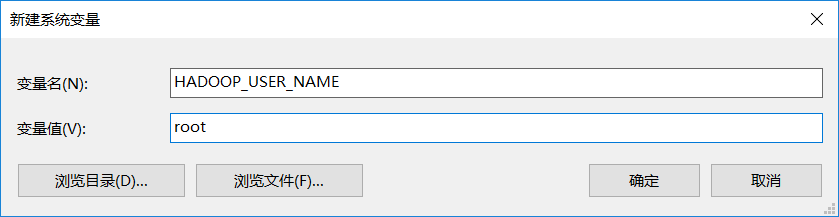
方式二:在JavaClient中添加环境变量
1 |
|
1.4.5. 解决方式4:JavaAPI指定用户名
1 |
|
1.5. 配置hadoop-common-bin
运行以下测试程序,第一条语句会出现错误 java.io.IOException: (null) entry in command string: null chmod 0644
1 |
|
hadoop-common-bin是hadoop在windows环境下编译的,用来在windows下运行hadoop程序的工具。下载大版本号相近的即可:https://github.com/amihalik/hadoop-common-2.6.0-bin
解压后的目录结构如下:
1 | . |
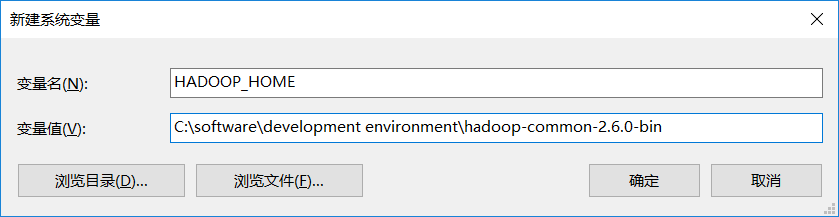
将该目录添加到环境变量中,取名HADOOP_HOME
将bin目录添加到PATH中,因为执行时用到 winutils.exe
1 | %HADOOP_HOME%\bin |
重启IDE,使IDE能读取到新的环境变量。再次运行testCopyToLocalFile,可以看到useRawLocalFileSystem为false也能成功将HDFS的文件下载到windows本地磁盘。
2. HDFS JavaAPI
2.1. 连接HDFS
连接HDFS只要指定NameNode的地址即可。
方式1:在core-site.xml中预先定义好NameNode的地址fs.defaultFS,或者直接复制服务器端的core-site.xml
1 |
|
方式2:通过Configuration的API设置fs.defaultFS
1 |
|
方式3:通过FileSystem.get(URI uri, Configuration conf)得到fs对象,第1个参数是HDFS的URI
1 | public static final String HDFS_PATH = "hdfs://hadoop1:9000"; |
无论是哪种方式连接,程序结束时都要记得关闭连接
1 |
|
2.2. mkdirs 创建目录
1 |
|
2.3. createNewFile 创建空文件
1 |
|
2.4. append 追加数据
1 |
|
2.5. copyFromLocalFile 从本地上传文件
1 |
|
2.6. copyToLocalFile 下载HDFS文件到本地
1 |
|
2.7. delete 删除文件或目录
1 |
|
2.8. rename 从HDFS一个路径移动到另一个路径
1 |
|
2.9. exists 判断文件是否存在
1 |
|
2.10. getFileStatus 获取文件属性
1 |
|
2.11. listStatus 列出目录下所有文件的属性
1 |
|
2.12. listFiles 列出目录下所有文件的属性
作用与listStatus()类似
1 |
|
2.13. create 通过IO流上传文件到HDFS
创建文件并写入数据
1 |
|
可实现文件上传。因为是IO流的形式,所以不限于上传本地文件,也可以是上传其它地方的文件到HDFS
1 |
|
2.14. open 通过IO流下载文件
1 |
|
HDFS JavaClient操作实例
分块下载文件
1 | /** |
对数据进行合并
1 | type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1 |
合并完成后,将hadoop-2.7.2.tar.gz.part1重新命名为hadoop-2.7.2.tar.gz。解压发现该tar包非常完整。


