1. 动态添加DataNode
在不关闭HDFS和YARN的情况下,动态添加DataNode
1.1. 先准备一台服务器hadoop4
| hostname | hadoop1 | hadoop2 | hadoop3 | hadoop4 |
|---|---|---|---|---|
| ip | 192.168.57.101 | 192.168.57.102 | 192.168.57.103 | 192.168.57.104 |
| system | ubuntu16.04 | ubuntu16.04 | ubuntu16.04 | ubuntu16.04 |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode | DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager | NodeManager |
- hadoop4配置静态ip、hostname
- 修改集群脚本:再多循环一个节点
- 各节点hosts添加hadoop4的记录
- NameNode和ResourceManager配置SSH免密码登录到hadoop4
- 复制集群jdk、Hadoop到hadoop4
- hadoop4删除hadoop同步得到的logs和data目录,一定要删除
- hadoop4配置环境变量
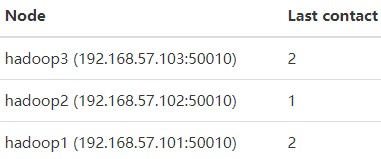
查看web ui,现在只有3个DataNode
1.2. 动态添加DataNode
启动服务。因为core-site.xml中已经指明了NameNode的地址,所以启动DataNode后,会直接向NameNode注册
1 | hadoop-daemon.sh start datanode |
查看进程。如果发现datanode没有启动,很可能是该节点原本的logs和tmp目录忘了删除了
1 | # jps |
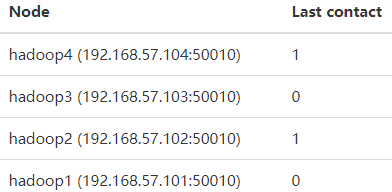
查看WebUI,可以看到DataNode添加成功
再启动nodemanager。因为yarn-site.xml已经指定了ResourceManager,所以启动nodemanager时会向其注册
1 | yarn-daemon.sh start nodemanager |
ResourceManager查看nodemanager
1 | yarn node -list |
1.3. 集群的再平衡
动态添加了DataNode,可能其它DataNode数据很多,但是新的DataNode没有数据,导致不平衡。此时NameNode执行以下命令,实现数据块的再平衡
1 | start-balancer.sh |
1.4. 测试上传文件
在新节点上执行上传文件
1 | hdfs dfs -put 2.txt / |
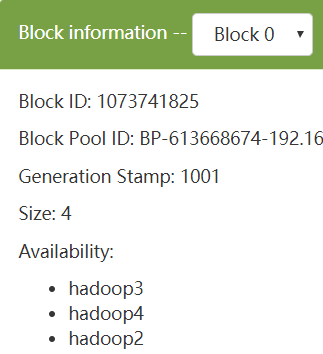
可以看到数据有3个副本。因为当前client是在datanode节点上执行的,根据就近原则,一定有一个副本是放在当前节点上
1.5. 编辑slaves
在slaves中添加节点,以便下次HDFS重启能一起启动hadoop4。
1 | hadoop1 |
2. 动态解除DataNode
2.1. 通过白名单解除DataNode
NameNode创建etc/hadoop/dfs.hosts,文件名无所谓,但是最好取官方默认的名称。写入以下内容,一行一个节点,只有白单名中的DataNode才有权连接NameNode,所以不添加hadoop4节点。注意不能有多余的空行,每行不能有多余的空格
1 | hadoop1 |
在NameNode的hdfs-site.xml中增加dfs.hosts配置
1 | <property> |
分发hdfs-site.xml
1 | xsync etc/hadoop/hdfs-site.xml |
refreshNodes动态刷新dfs.hosts和dfs.hosts.exclude配置,无需重启NameNode
1 | hdfs dfsadmin -refreshNodes |
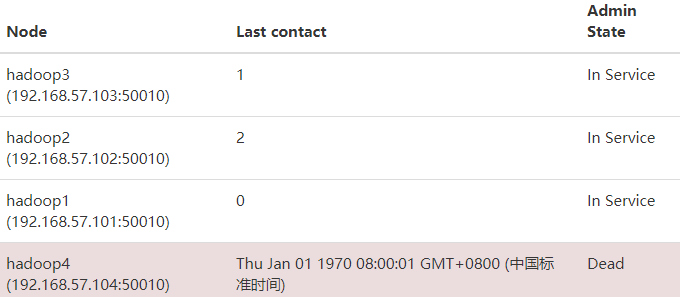
刷新后,查看WebUI,hadoop4被删除了
hadoop4查看进程
1 | $ jps # DataNode被关闭了,只剩下NodeManager |
NameNode执行再平衡
1 | start-balancer.sh |
一般解除节点是通过黑名单,而不是白名单,所以不推荐使用白名单的方式来解除节点
2.2. 恢复刚才被白名单解除的DataNode
NameNode编辑dfs.hosts,添加hadoop4
1 | hadoop1 |
NameNode刷新
1 | hdfs dfsadmin -refreshNodes |
hadoop4启动DataNode
1 | hadoop-daemon.sh stop datanode |
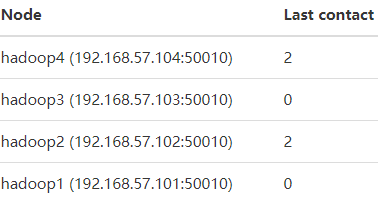
查看web ui,看到hadoop4恢复了
2.3. 通过黑名单解除DataNode
先去掉白单名
- 编辑hdfs-site.xml,删除dfs.hosts配置。分发hdfs-site.xml
- NameNode刷新
hdfs dfsadmin -refreshNodes
NameNode创建etc/hadoop/dfs.hosts.exclude,文件名无所谓,但是最好取官方默认的名称。每一行代表黑名单中的节点。现在要将hadoop4加入黑名单
1 | hadoop4 |
NameNode编辑hdfs-site.xml,添加dfs.hosts.exclude属性
1 | <property> |
分发
1 | xsync etc/hadoop/hdfs-site.xml |
NameNode刷新
1 | hdfs dfsadmin -refreshNodes |
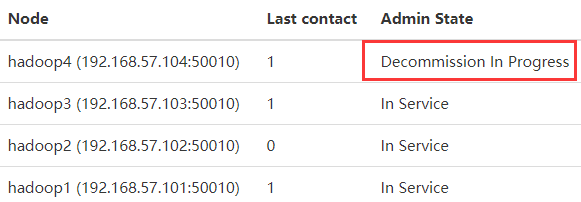
查看web ui,看到状态是Decommission In Progress,表示正在解除hadoop4。此时HDFS会把hadoop4中的数据块复制到其它DataNode上,hadoop4中的数据越多,该过程就越漫长
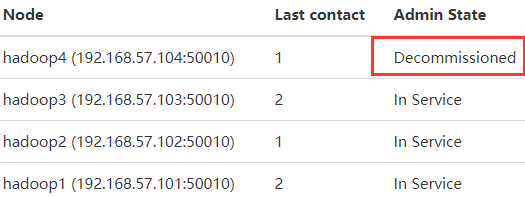
过一段时间后,状态变为Decommissioned,即正式解除
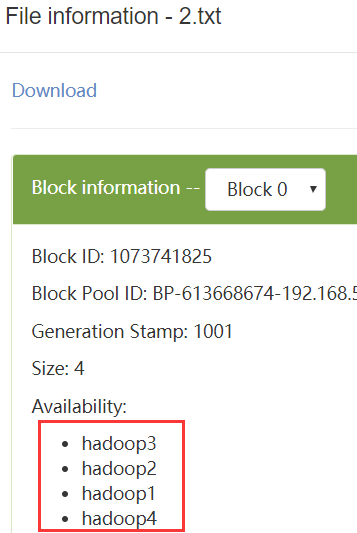
可以看到hadoop4将块副本拷贝给hadoop1
NameNode执行再平衡
1 | start-balancer.sh |


