1. Hadoop目录结构
1 | . |
2. Hadoop基本环境搭建
- 安装jdk 1.8
- 安装hadoop
2.1. 编辑etc/hadoop/hadoop-env.sh
1 | # 修改JAVA_HOME,这样hadoop才能找到JVM |
2.2. 编辑etc/hadoop/mapred-env.sh
1 | # 修改JAVA_HOME |
2.3. 编辑etc/hadoop/yarn-env.sh
1 | # 修改JAVA_HOME |
3. Hadoop本地模式(Standalone)搭建
刚安装完Hadoop,什么都不配置,默认就是本地模式。
这里的本地模式有两个意思
- HDFS直接使用本地文件系统。因为fs.defaultFS的默认值是file:///
- MapReduce运行在本地,而不是YARN。因为mapreduce.framework.name的默认值是local
3.1. 编辑/etc/hosts
查看当前主机的hostname
1 | $ hostname # 查看当前主机名 |
编辑/etc/hosts,为当前主机名添加一条记录。若没有,运行本地MapReduce时会出现java.net.UnknownHostException 错误
1 | 192.168.57.100 ubuntu # 为主机名添加一条记录 |
3.2. 准备数据
创建input目录
1 | cd /usr/local/hadoop |
创建 input/1.txt
1 | one |
创建 input/2.txt
1 | apple |
3.3. 官方grep案例
运行grep案例。将input目录下所有文件作为输入,按行遍历,找出所有符合 正则表达式'o.+'的字符串,输出到output目录。注意运行前output目录不应该存在,否则运行会出现FileAlreadyExistsException错误
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'o.+' |
查看生成的output目录
1 | $ ls -l output/ |
查看结果
1 | $ cat output/part* |
3.4. 官方WordCount案例
运行wordcount案例。将input目录下所有文件作为输入,输出到output目录
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount input output |
查看结果
1 | $ cat output/part* |
4. Hadoop伪分布模式(Pseudo-Distributed)搭建
伪分布式所有服务仅在1台机器上运行,但是配置与完全分布式类似
4.1. 为主机名添加DNS记录
编辑/etc/hosts,要为当前主机名添加一条记录
1 | 192.168.57.100 ubuntu |
HDFS客户端也要编辑hosts文件,同样要添加DNS记录。因为之后客户端访问HDFS时,NameNode会让client去找DataNode(去找主机名为ubuntu的主机),如果没有添加记录,client就无法访问DataNode
1 | 192.168.57.100 ubuntu |
4.2. 配置ssh本机免密码登录
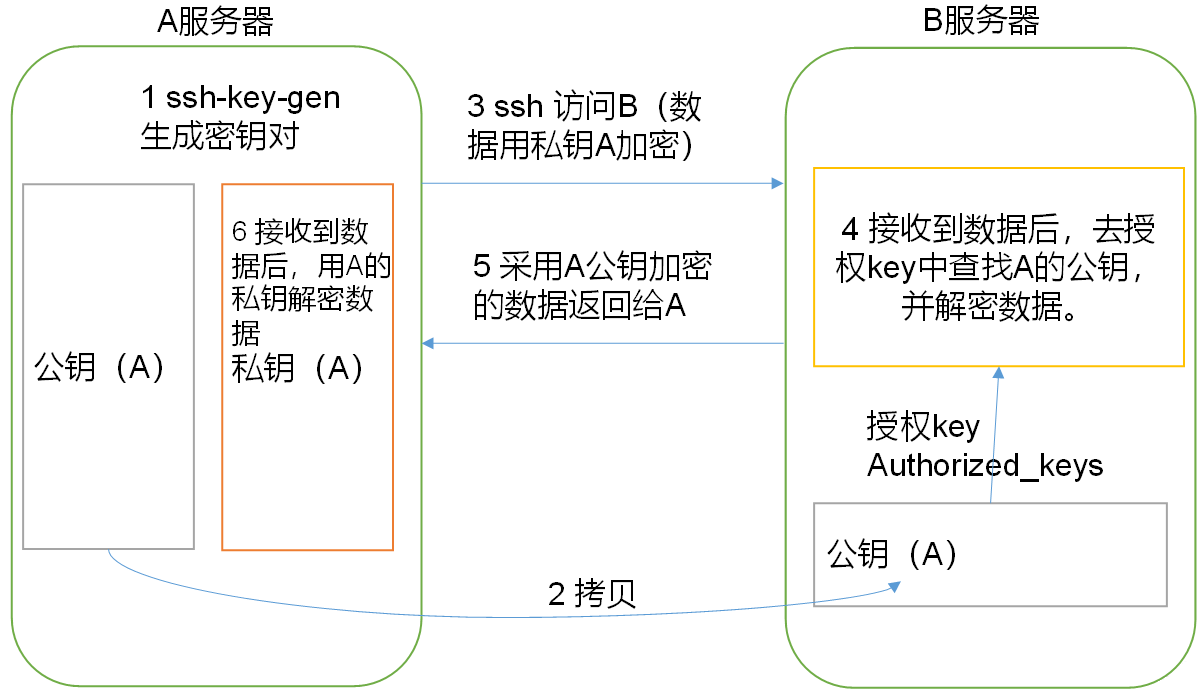
SSH免密钥登录原理:
- A使用ssh-key-gen命令生成密钥对
- A将公钥拷贝到B的authorized_keys中
- A使用SSH访问B时,用私钥对数据加密
- B收到数据,从authorized_keys中找到A的公钥,对数据解密
- B给A一个回复,回复的数据用A的公钥加密
- A收到B的回复,用私钥解密。到此,A就成功连接上了B。
所以A想要免密钥登录B,需要预先将自己的公钥发送到B的authorized_keys中
运行ssh服务
1 | # 选以下任意一条命令即可 |
设置本机免密码登录
1 | ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa |
登录本地测试。默认情况下,ssh开启StrictHostKeyChecking yes,所以首次连接时会询问yes/no,回答yes即可
1 | ssh localhost |
4.3. 编辑etc/hadoop/core-site.xml
1 | <configuration> |
4.4. 编辑etc/hadoop/hdfs-site.xml
1 | <configuration> |
4.5. 格式化NameNode
HDFS的格式化和系统磁盘的格式化含义是一致的。
NameNode节点上,有两个最重要的路径
- dfs.namenode.name.dir:存储元数据信息
- dfs.namenode.edits.dir:存储操作日志
格式化时,NameNode会清空两个目录下的所有文件,之后,会在两个目录下创建以下文件:
1 | {dfs.namenode.name.dir}/current/fsimage # 存储命名空间(目录和文件)的元数据信息 |
因为默认${dfs.namenode.edits.dir}=${dfs.namenode.name.dir},所以两个目录实际上是同一个目录。所以只会看到这些文件
1 | {dfs.namenode.name.dir}/current/fsimage # 存储命名空间(目录和文件)的元数据信息 |
所以格式化NameNode分两种情况:
- 首次格式化:HDFS文件系统fsimage还不存在,需要格式化生成文件系统,之后才能对HDFS进行操作。
- 再次格式化:清空HDFS文件系统的所有数据。
4.5.1. 首次格式化的操作
现在HDFS的文件系统还不存在,所以要先格式化NameNode。
1 | # 以下两条命令等价,选择一条执行即可 |
看到以下信息,说明格式化成功
1 | INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted |
查看格式化生成的文件
1 | # tree tmp/ |
4.5.2. 再次格式化的操作
第一步:先关闭Hadoop集群
第二步:再删除日志目录logs和${hadoop.tmp.dir}。注意一定要先关闭集群,不然一删除,logs和tmp目录又会生成。
1 | rm -rf logs/ # 删除logs |
第三步:再次格式化
1 | hdfs namenode -format |
4.5.3. 格式化前不删除tmp目录的后果
在NameNode格式化后,会生成一个clusterID。之后DataNode和SecondaryNameNode与NameNode通信后,会生成相同的clusterID。
1 | $ find tmp/ -name 'VERSION' |
如果不删除tmp目录,直接格式化NameNode,那么NameNode会生成新的clusterID,与DataNode和SecondaryNameNode的clusterID就不一致了。重启启动集群时,就会报错 java.io.IOException: Incompatible namespaceIDs,导致集群无法启动。
4.6. 启动HDFS服务
启动HDFS服务
1 | start-dfs.sh |
查看进程
1 | $ jps |
访问 NameNode的WebUI,默认端口50070
4.7. 在本地运行MapReduce
在mapred-default.xml中,mapreduce.framework.name默认值是local,所以MapReduce默认在本地运行。
在本地运行MapReduce
1 | hdfs dfs -put input / # 上传之前的input目录 |
4.8. 编辑etc/hadoop/mapred-site.xml
默认只有模板文件,所以先复制得到一份配置文件
1 | cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml |
编辑 etc/hadoop/mapred-site.xml
1 | <configuration> |
4.9. 编辑etc/hadoop/yarn-site.xml
1 | <configuration> |
4.10. 在YARN上运行MapReduce
之前已经配置了在YARN上运行MapReduce,现在尝试运行MapReduce
1 | hdfs dfs -put input / # 上传之前的input目录 |
因为YARN还没有启动,所以运行MapReduce后,会一直尝试连接YARN。CTRL+C 结束尝试。
1 | INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032 # 不断重复出现Retrying connect 信息 |
启动YARN
1 | start-yarn.sh |
再次运行MapReduce,成功
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input /output |
4.11. 配置MapReduce历史服务器
在配置启动JobHistory服务之前,YARN的WebUI界面里是无法查看作业的历史信息的

4.11.1. 编辑etc/hadoop/mapred-site.xml
1 | <property> |
4.11.2. 启动历史服务器
启动
1 | mr-jobhistory-daemon.sh start historyserver |
查看进程
1 | $ jps |
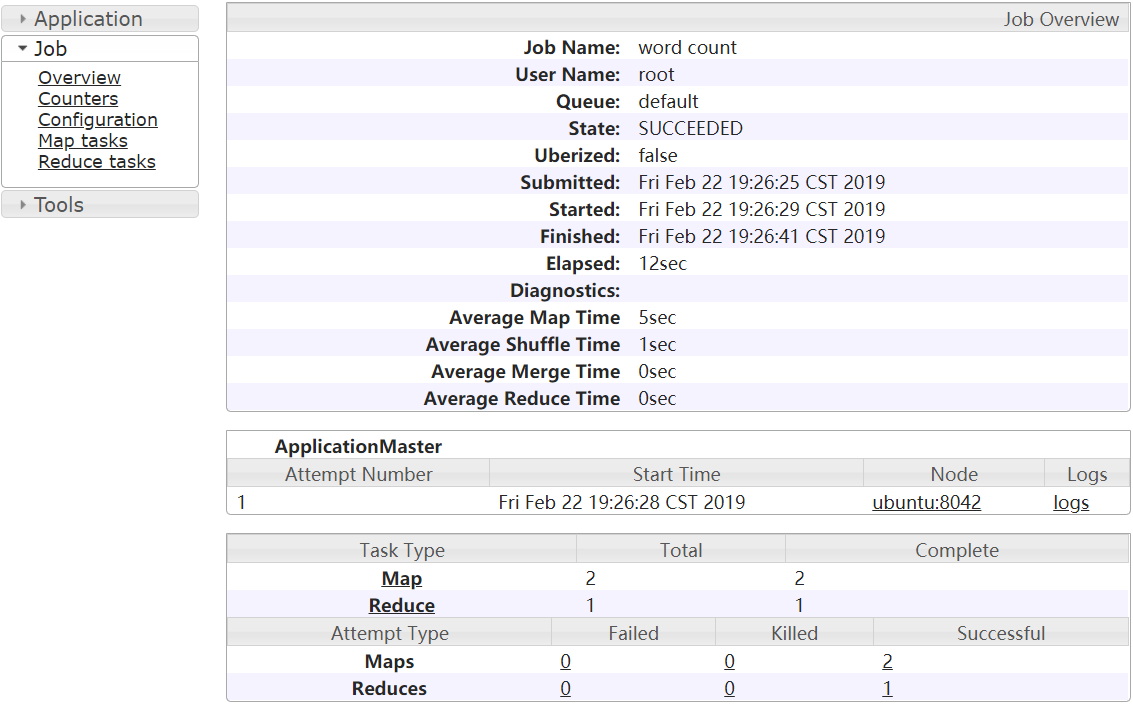
再次点击查看history
即可看到history的Overview主界面
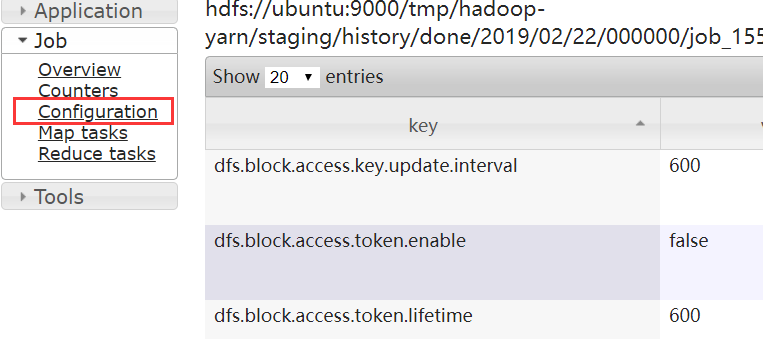
Counters界面:查看各个计数器信息
Configuration界面:该作业在运行时,所有的配置信息
Map tasks界面:各个Map任务的运行信息
Reduce tasks界面:各个Reduce任务的运行信息
4.12. 配置YARN日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager
4.12.1. 关闭相关服务
1 | mr-jobhistory-daemon.sh stop historyserver |
4.12.2. 编辑etc/hadoop/yarn-site.xml
1 | <property> |
4.12.3. 启动相关服务
1 | start-yarn.sh |
4.12.4. 再次运行WordCount
1 | hdfs dfs -rm -r -f /output |
4.12.5. 通过Web查看日志
先进入history页面

再进入logs页面
进入日志页面。默认只显示4096字节的日志信息,可点击查看完整日志
4.13. 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| core-default.xml | hadoop-common-2.7.2.jar/ core-default.xml |
| hdfs-default.xml | hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
5. Hadoop完全分布式搭建
5.1. 集群规划
| hostname | hadoop1 | hadoop2 | hadoop3 |
|---|---|---|---|
| ip | 192.168.57.101 | 192.168.57.102 | 192.168.57.103 |
| system | ubuntu16.04 | ubuntu16.04 | ubuntu16.04 |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
原则:NameNode、SecondaryNameNode、ResourceManager最好分别处在不同的节点上
5.2. 配置静态ip
编辑 /etc/network/interfaces
1 | # hadoop1 |
5.3. 配置hostname
编辑 /etc/hostname
1 | # hadoop1 |
5.4. 创建集群分发脚本xsync
因为 /usr/local/bin目录在$PATH中,该目录下的命令可以直接执行,所以创建 /usr/local/bin/xsync,写入以下内容
1 |
|
添加可执行权限
1 | chmod 755 /usr/local/bin/xsync |
5.5. 创建集群执行同一命令的脚本xcall
创建 /usr/local/bin/xcall
1 |
|
添加可执行权限
1 | chmod 755 /usr/local/bin/xcall |
命令测试
1 | xcall echo 111 '>' ~/1.txt |
5.6. 添加hosts记录
编辑 /etc/hosts,添加以下记录
1 | 192.168.57.101 hadoop1 |
同步 /etc/hosts
1 | xsync /etc/hosts |
同步xsync脚本
1 | xsync /usr/local/bin/xsync |
5.7. 配置SSH免密码登录
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
hadoop1是NameNode,故要能够免密钥登录到所有的HDFS节点(包括自身NameNode 、DataNode、SecondaryNameNode)
hadoop2是NodeManager,故要能够免密钥登录到所有的YARN节点(包括自身ResourceManager、NodeManager)
hadoop1和hadoop2执行以下操作
1 | # 生成密钥对 |
5.8. 安装jdk
安装jdk,同步jdk和环境变量
1 | xsync /usr/lib/java |
各节点使环境变量生效
1 | source /etc/profile |
5.9. 安装并配置hadoop
安装hadoop,配置基本环境,与之前的操作一样
1 | ### 编辑etc/hadoop/hadoop-env.sh |
同步hadoop和环境变量
1 | xsync /usr/local/hadoop |
各节点使环境变量生效
1 | source /etc/profile |
5.9.1. 编辑etc/hadoop/core-site.xml
1 | <configuration> |
5.9.2. 编辑etc/hadoop/slaves
编辑slaves,一行一个datanode和nodemanager。注意:文件中不允许有空行,每行后面不允许有多余的空格。
1 | hadoop1 |
5.9.3. 编辑etc/hadoop/hdfs-site.xml
1 | <configuration> |
5.9.4. 编辑etc/hadoop/mapred-site.xml
默认只有模板文件,所以先复制得到一份配置文件
1 | cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml |
编辑 etc/hadoop/mapred-site.xml
1 | <configuration> |
5.9.5. 编辑etc/hadoop/yarn-site.xml
1 | <configuration> |
5.9.6. 同步hadoop
因为操作了很多文件,直接将整个hadoop同步一下
1 | xsync /usr/local/hadoop |
5.9.7. 格式化NameNode
在格式化之前注意:
- 确保各个节点的服务都于关闭状态
- 确保各个节点的logs和tmp目录已删除
hadoop1(NameNode)执行格式化命令
1 | hdfs namenode -format |
5.9.8. 启动HDFS
hadoop1(NameNode)执行
1 | start-dfs.sh |
查看进程
1 | $ jps # hadoop1 |
5.9.9. 启动YARN
hadoop2(ResourceManager)执行
1 | start-yarn.sh |
查看进程
1 | $ jps # hadoop1 |
5.10. 集群基本测试
input目录里有两个小文件
1 | $ ls -l input |
上传input目录
1 | hdfs dfs -put input /input |
Web查看。因为是小文件,所以都只有1个数据块,在3个DataNode上各有1个副本
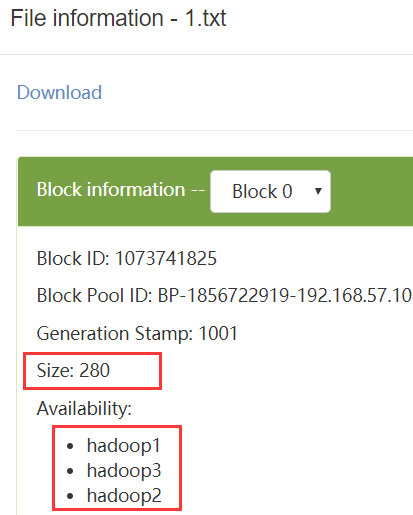
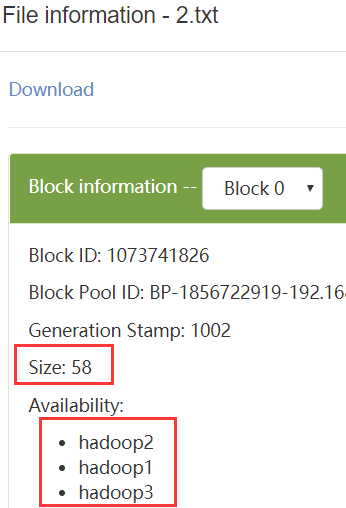
查看块数据文件
1 | $ ls -l tmp/dfs/data/current/BP-1856722919-192.168.57.101-1550860466565/current/finalized/subdir0/subdir0 |
1 | cat blk_1073741825 # 1.txt的内容 |
上传大文件
1 | $ ls -lh hadoop-2.6.5.tar.gz |
1 | hdfs dfs -put hadoop-2.6.5.tar.gz / |
Web查看。191M的文件被分成2块,在3个DataNode上各有1个副本
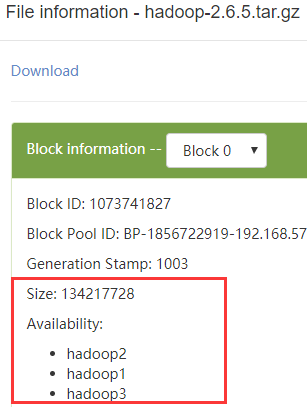
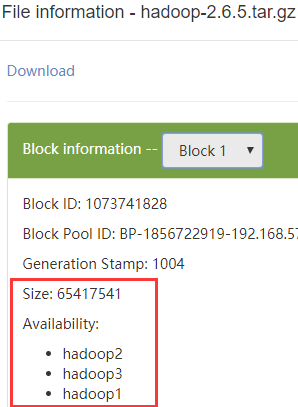
查看块数据文件
1 | $ ls -l tmp/dfs/data/current/BP-1856722919-192.168.57.101-1550860466565/current/finalized/subdir0/subdir0 |
1 | cat blk_1073741827 blk_1073741828 >> tmpfile # 拼接两个block,得到完整文件 |
5.11. 集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
5.11.1. 时间服务器配置
让hadoop1作为时间服务器
5.11.1.1. 安装ntp
1 | dpkg -l | grep ntp # 查看是否安装ntp |
5.11.2. 编辑/etc/ntp.conf
修改1:授权 192.168.57.0/24 网段操作权限
1 | ### 授权方式是否定式的,如果不做任何限制,就是所有权限 |
修改2:集群在局域网中,不使用其他互联网上的时间
1 | # 默认会使用互联网上的时间,将以下语句注释 |
修改3:当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
1 | server 127.127.1.0 |
5.11.2.1. 重启ntp服务
1 | systemctl restart ntp |
5.11.3. 其他机器配置
hadoop2、hadoop3是客户端,根据hadoop1校时
5.11.3.1. 安装ntpdate
1 | apt-get install -y ntpdate |
5.11.3.2. 测试ntpdate校时
1 | timedatectl set-ntp no # 默认开启NTP时间同步,先将其关闭,才能修改系统时间 |
5.11.4. 设置校时计划任务
开启cron服务
1 | systemctl start cron |
crontab -e 添加计划任务,每10分钟通过hadoop1进行校时
1 | # 注意命令要写绝对路径/usr/sbin/ntpdate,而不是写为ntpdate,因为crontab不会读取$PATH变量,会出现找不到ntpdate的情况 |


